


Deepseek-R1

I jotted some notes down on my X account, which I am writing here as well, with a few more thoughts.
Deepseek has done it again! They released Deepseek-R1 and Deepseek-R1-zero, two reasoning models.
Link: https://github.com/deepseek-ai/DeepSeek-R1
No SFT
We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step.
Even though it’s clearly laid out, this will take some time to sink in. Nathan from AI2/Interconnects has been talking about using RL for finetuning, and OpenAI also mentioned that they have a new form of fine-tuning called “RFT” (Reinforcement Finetuning).

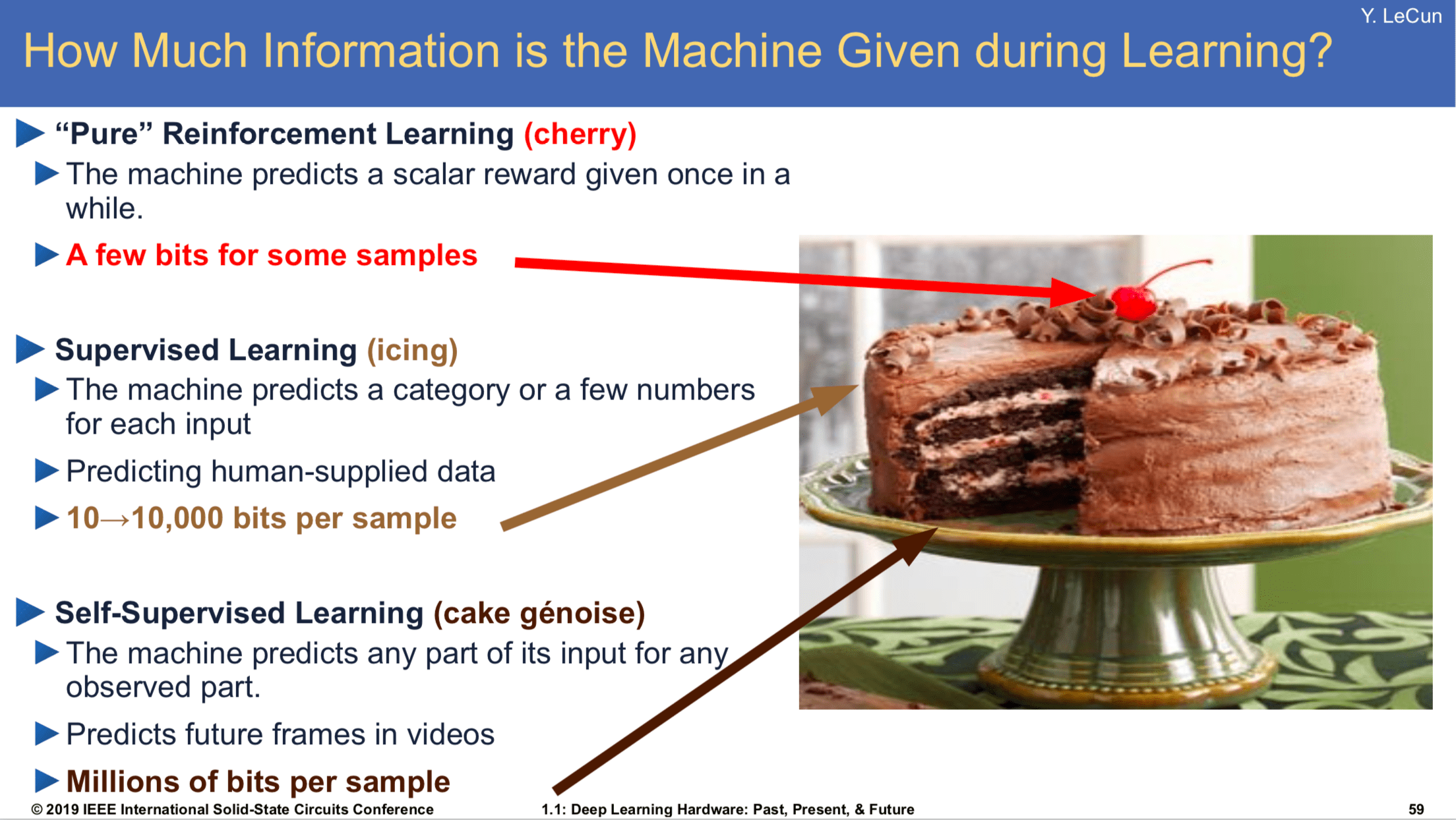
SFT has always been considered a staple for training LLMs. Now this is upended by saying we don’t need it. Reminds me about Yann’s statement that RL is the cherry on top of the cake. We don’t need the icing?!
There are of course many questions. For example, perhaps SFT data got mixed into the pretraining data? What kind of base models do we need to see this benefit?
Note that Deepseek-R1 has some SFT in it, and Deepseek-R1-zero is purely RL.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning. With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing.
Insane.
2025 will be the year of RL and reward shaping is going to be very important.
Note that RL is great for reasoning, and there are many problems where reasoning is not needed or not useful, and SFT is still useful in those cases.
Distillation is going to be huge.
Distillation has been quite helpful for a long time, but distillation of reasoning models is a bit new and extremely powerful.
This was one reason why OpenAI was not allowing users to look at the reasoning traces. I will write more about this a bit later.

And we are going to make distillation as easy as possible with Curator.
No Process Reward Models or MCTS
Another big surprise from the paper is that they didn’t use process reward models (which was popularized by openai in their Let’s verify step by step paper) or MCTS.

They use instead what’s called GRPO.
And lastly, here’s a quick colab that uses Curator to start generating data using Deepseek-R1.