
What DeepSeek means for the world


DeepSeek-R1 dropped on Jan 20, a sleepy Monday morning for many in the US because it was an MLK holiday. And the world changed, most definitely, on that day.
I thought it would be fun to do a very comprehensive post on what DeepSeek-R1, and more broadly, reasoning means for X, where X is just about everything I can think of. I was also inspired to do this after watching this amazing podcast from Lex Fridman featuring Nathan Lambert and Dylan Patel, and some of the ideas/answers here are from there.
Before proceeding ahead, here are a few things you want to know about DeepSeek-R1. DeepSeek-R1 is a reasoning model. Chain-of-thought has existed for a long time, but I think of it as a linear process going from the question (prompt) to the answer (response). If a step is incorrect, everything falls apart from then onwards. With reasoning, the model does all sorts of backtracking, verification, subgoal setting, etc. See this if you want to read a reasoning trace — the model’s stream of consciousness.
A technique used to unlock reasoning is Reinforcement learning. This starkly contrasts with SFT (supervised fine-tuning) in that in SFT, you show the model a prompt and a response, whereas in RL, you don’t need the response—just judge and reward the response.
A mental model I use is that:
Pretraining helps a model learn knowledge.
SFT helps the model learn how to behave and
RL helps the model reason.
An equivalent analogy is that this is like going to school to learn, learning to do a craft by seeing how it’s done, and finally learning by trial and error, respectfully.
This is all an approximation, as we have seen that SFT sometimes helps learn new knowledge and distillation (described later) — done via SFT — also induces reasoning.
Note that LLM training consists of two stages: pretraining and posttraining. SFT and RL belong in the post-training stage. A small clarification is that RLHF (and the variant called DPO) is also part of the post-training stage. While RLHF has been around for a while (and uses RL), the new form of using RL is slightly different.
DeepSeek-R1 uses an RL technique called GRPO. While RLHF has never been seen as an alternative to SFT, DeepSeek-R1 showed that it’s actually possible to avoid SFT and do RL—to some extent (there are many caveats here, which we won’t go into now). For those outside of frontier labs, the newsworthiness of this was similar to a Richter 8 earthquake.
Now let’s begin!
What it means for Pretraining
As we know, pretraining is hitting a wall. We have entered a territory where the improvement, which is scaling as the log of model size and compute, is not really optimal. There were rumors that Orion (OpenAI’s next-generation pre-trained model) was struggling.
The words optimal and struggling indicate a subjective reality, not an objective one. It’s not objective, since the scaling laws unfortunately have a log x-axis. It’s just that instead of spending $1B, one now has to spend $10B to pretrain a new model, which improves Elo scores on LMSYS by a few points. What gives?
We did see that happen with OpenAI’s botched GPT-4.5 release: the model is just too expensive and too slow (and paradoxically, people felt the model was not good), and the model seems to have gone up in lmsys rankings.
As you can see from the figure I put together from OpenAI’s system card and Anthropic’s system card for Claude 3.7 Sonnet, GPT-4.5 is actually worse than DeepSeek-R1 in terms of SWE-bench verified, an important coding benchmark.
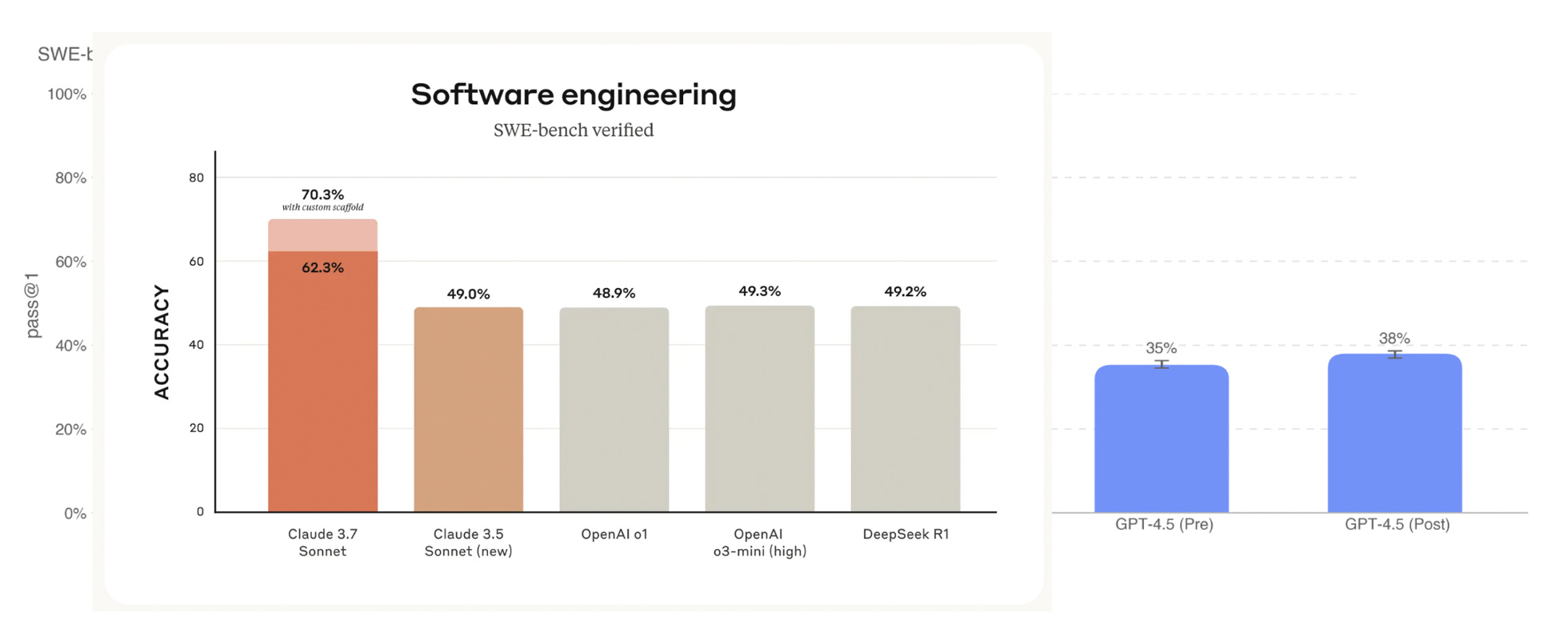
This comparison is not entirely fair because GPT-4.5 hasn’t been post-trained with reasoning. o1, which is based on a GPT4-series model, is however post-trained for reasoning tasks (which is useful for SWE-bench).
Why is this important and relevant to reasoning? We see that reasoning, which is attained with RL in post-training, can improve the quality of the models much more cost-efficiently. In general, post-training has more bang for the buck due to where we are with respect to the scaling laws.


In foundational model companies, pre-training and post-training are done by separate teams, and so I suppose the pre-training teams are feeling the pain right now.
The other impact is in how exactly pre-training is done, especially with respect to data curation. Reasoning data is going into pre-training (probably in the mid-training stage: this recent work shows that you can add reasoning data into mid-training, aka CPT—continual pretraining—to make non-reasoning models better).
What it means for Post-training
The magic of DeepSeek-R1 is in the post-training.
Given what I mentioned above about the cost-benefit tradeoff, post-training seems like a better place to invest compute, time, and resources. And RL fits squarely here, and so DeepSeek-R1 is causing post-training, especially towards reasoning/thinking models, all the rage right now.
People are also doing SFT using reasoning data, to create thinking models. One of the first amongst them was us :). This is type of distillation, so will cover this more later.
What it means for RL
RL is several decades old. It became sort of a hot topic in 2016 or so, thanks to DeepMind (AlphaGo especially), and then it faded away a bit. Only now, it’s all the rage. I personally think RL is how we get AGI.
If you remember the cherry on the cake analogy from Yann LeCun, he pretty much called it correctly.

In this image, self-supervised learning is pretraining (and supervised learning is SFT). The community first built the bottom (which took the lion’s share of compute resources), then worked on SFT and is now doing RL.
RL has been used in RLHF, but it did feel like an afterthought. DPO was working reasonably fine (but not as good as PPO).
What it means for building Agents
OpenAI has this great chart on the five levels of AI:

Everyone and their nephew went straight from prompting models (level 1) to building agents (level 3). I suppose by now, they have realized that agents are hard to make work well (prompting works only so well). Only now are we improving upon reasoning (level 2), and so I think now is the time to start building and betting on agents.
Agents plan and break down a given task into steps. This is essentially reasoning. You want the agent to recover from mistakes (backtracking, etc.), and this is where reasoning models shine.
In terms of building agents, this is how things change: a vast majority of users have been prompting the models to death and trying to make them behave in a specific manner when building agents. It’s like you telling me to do something, and if I don’t do well, you don’t give me feedback but start from scratch and tell me again what I should do using a different set of words.
Some advanced users have been using SFT for building agents (e.g., Devin). Here, you show the model how to behave. However, when you want an agent to take many steps, creating the data that describes the different combinations is hard. This is where RL enters the picture.
We are working on this. Contact me if you are interested.
What it means for Long-context
Reasoning models are a good unlock for agents. And what do agents need? Good long-context performance. In agent loops, you take action, get feedback, and add that into the context, gradually increasing the tokens in the input. Of course, the reasoning models talk a lot, so the context grows quite fast.
Long context models exist, but their performance degrades when the context lengths are long. So, we will need better long-context models.
What it means for Distillation
Distillation was introduced in 2015 by Hinton. I worked on it at Google almost five years back. We used it to train the Bespoke-MiniCheck model. So it’s been always there, but it’s pretty popular now!
Distillation, as implemented traditionally, is slightly different, but here we have a simpler definition: we use a large model to generate data and use that to finetune a smaller model.
Sky-T1 distilled the Qwen reasoning model into the Qwen non-reasoning model. They showed that you can make non-reasoning models to reason just by SFT (so this is distillation), instead of needing anything fancier (like RL or search).
We took a very similar approach and created the Bespoke-Stratos dataset and the model (blog). We also announced Open Thoughts, whose datasets for distillation have been well received (still trending on HuggingFace, as of this writing, well after over a month).
I think, overall, this is an excellent direction of research and utility. We can train large models with RL and then distill them into smaller models.
What it means for OpenAI
Obviously, R1 puts a lot of pressure on OpenAI for two reasons. On the benchmarks, R1 matches o1. And to reiterate, that’s a big deal. Because OpenAI spent a lot of time and money into building it and marketing it as a flagship model, we have an open-source equivalent model that’s completely free, trained for far less money, and can run on commodity hardware.
And second, DeepSeeks’ app catapulted to the top and became more popular than ChatGPT! OpenAI has been trying to become a consumer brand, and so DeepSeek getting to the top spot is not fun for them.
So, they had to accelerate the release of the o3-mini and drop the prices. OpenAI also budged to the pressure, and Sam has said they will open-source a model. Let’s see how if they live up to the promise. And they were pretty stringent earlier about not showing reasoning traces (people used to get ominous warnings if they tried to access the reasoning traces). o3-mini now shows reasoning traces, thanks to DeepSeek.
So the pressure on OpenAI is real. But for what it’s worth, OpenAI still have a few things going for them:
Very good people working there.
Sam Altman who can move mountains
Insanely good training and serving infrastructure.
But anyone and everyone can download R1 and use it. And Bespoke Labs and others are distilling capable models that can run on regular Macbooks. All of this should definitely put a lot of pressure on OpenAI.
Moreover, OpenAI has been raising more and more money. And DeepSeek just showed that you can do a lot with a lot less. So, I suspect some investors are asking questions.
What it means for Anthropic
Anthropic has always said safety is paramount for their models. They train models and then spend many, many months testing for safety (it seems almost a year!). But if DeepSeek and other open-source models drop the next day after training is done and will displace Claude's usage, then Anthropic has a lot of reasons to move much faster by sacrificing safety aspects.
If you think safety is essential, then Dario Amodei’s recent essay on the USA's need to increase its sanctions on China is worth checking out.
What it means for Meta and Llama
After DeepSeek, OpenAI has made a number of announcements. Grok 3 was released, and Anthropic announced the Claude Sonnet 3.7 model with thinking mode. But we are yet to hear anything from Meta. I suspect Llama 4 timelines have been accelerated, and they should have dropped it by now, but they haven’t. And they should be worried.

Zuckerberg has written about being open-source friendly, but Llama models have a weird license compared to DeepSeek. If you finetune a llama model or generate tokens from a llama model and finetune your model, the resulting model has to have llama in the name (which is why we had to name our model as Llama-3.1-Bespoke-MiniCheck-7B; this was confusing to many since llama-3.1 models are not 7B in size but 8B but we had to use this name since we generated data using the Llama 405B model). In sharp contrast, DeepSeek used an MIT license and said do whatever you want to do!
So, concretely, DeepSeek must have accelerated the timelines of Llama 4 (which is good for the rest of us), and I hope they can improve their license (though they may not).
What it means for Microsoft
Microsoft added R1 to its catalog of models in Azure (link). This is interesting, given that Microsoft has been investing in and is spending a lot of money on supporting OpenAI. They have been a bit too tightly coupled with OpenAI, and Satya is starting to sing differently now.
He recently said AI is not living up to its promises and that these benchmarks are useless (see his podcast with Dwarkesh Patel). He wants to see real improvements in GDP (oh dear). Microsoft has also been pulling back on data center leases (link).
Overall, I think Microsoft is not going to double down on its past investment (OpenAI) but will try to hedge and be open to using many other models.
What it means for xAI
In many respects, xAI/Grok seems to be the opposite of DeepSeek. While DeepSeek managed to train a model with thousands of GPUs, xAI built a cluster with a hundred thousand GPUs.
xAI entered this race nine or ten months ago and used brute force to reach a very good position. We have to wait and see if xAI will adopt a different mindset now and try to make things much more efficient. Elon has also been known to do that (at least at Tesla and SpaceX).
What it means for Gemini
Gemini had already created a pretty good thinking model, but people didn’t pay enough attention. Unlike OpenAI, which used to hide reasoning traces, Gemini has always allowed users to actually see the traces. Yet people still didn’t talk about it as much as DeepSeek. This is where DeepSeek’s marketing shines (like when they say no ivory towers—just pure garage-energy and community-driven innovation; they seem to electrify the community)!
Stanford’s s1 team introduced a quite competitive model compared to our Bespoke-Stratos model (which was annotated with DeepSeek-R1), and what’s interesting is that their data was actually annotated with Gemini.

Note that Bespoke Labs helped them create s1.1 using Curator with DeepSeek-R1, which does improve upon Gemini.
What it means for Open-Source
Open-source is thriving. After DeepSeek-R1, there have been many efforts on reproducing reasoning models (open-thoughts and open-r1, mentioned below), many efforts on producing good quality datasets, and lots of work using RL (e.g. TinyZero, DeepScaleR). There has been a flurry of activity, and it’s becoming hard to keep track of!
Also, DeepSeek could force the hand of OpenAI to open-source one of their models, which would also be a win for the community.
In general, we see many more people now excited about building, and the tooling is also starting to mature. For RL, there are three popular open-source libraries: VeRL, TRL from HuggingFace, and GRPO from Unsloth. And I suspect more will pop-up, and existing ones will keep improving.
Academia was feeling a lot of fomo earlier when they realized they can’t pre-train models, but now with distillation and RL runs that make smaller models work like magic, they are so back.
What it means for HuggingFace
HuggingFace thrives if open-source thrives. After DeepSeek-R1, they kicked off an open-source reproduction of R1, called open-r1. This has attracted much attention (22k stars on GitHub) and media coverage.
As open-source thrives, HuggingFace does—at least in the sense that people use a lot more of it. Every link goes back to HF. How they make money out of it is yet to be seen.
What it means for Researchers
Thanks to DeepSeek, Reasoning is a hot research topic now, and many people are getting into RL.
More research is needed along the following directions:
RL is way too expensive. How do we make it cheaper?
How do you deploy RL to enable real-world agents? (I have some news for you: prompting doesn’t work.)
Reward shaping
Efficiency for serving and training.
Long context (more on this below).
How do we curate data for reasoning, and what kind of data should be added to pretraining?
Also, if companies and frontier labs need to reduce their costs, would they start paying researchers less now?
What it means for GPUs
On Jan 27, Nvidia stock sold off for $600B due to concerns that DeepSeek showed you can train models on a budget. What’s absurd is that DeepSeek had reported about their $6M pretraining run for DeepSeek-V3, not R1. Investors responded after a month.
For a while, Jevons paradox became popular. I agree with it as well — overall usage will go up, and GPUs will be more in demand, not less.
Let’s break it down into training and inference.
For training: RL seems to be mind-numbingly expensive. As more people start to use RL to train models and agents on their tasks, more GPUs will be required. Test-time computing is also more expensive, so we need more GPUs. Distillation should ease the pressure, but we will have a lot of distilled models.
For inference: Cerebras, Groq, and new players are coming in. Nvidia is also obviously used widely for inference, and they are going to try to expand more here.
Let’s focus a bit on GPUs. What kind of GPUs are we going to see? For one, it seems like people are getting excited about cheaper GPUs ( “Gaming chips” are starting to get smuggled in china).
Taking a step back, these are four parameters to consider when deciding what kind of GPU to use for inference:
FLOPs: the raw compute power
Memory: how much memory is there in GB
Memory bandwidth: how fast things move around
Interconnect: if a model doesn’t fit in one GPU, you need multiple GPUs to serve them. So how are they interconnected (NVLink, PCI-e)? And how are different nodes interconnected (infiniband)?
While pretraining is all about the raw FLOPs, memory capacity, and memory bandwidth become critical for inference. Reasoning models put a lot of pressure on the memory bandwidth, so GPUs with higher memory and memory bandwidth are a better fit for reasoning models. DeepSeek has had access to H20 instead of the shinier H100. The H20s do sound inferior (from moomoo):
In terms of specific performance metrics, the H20 AI chip is a kind of tweaked version of the H100. According to measurement organizations, the H20's combined arithmetic power is about 80% lower compared to the H100.
But in reality:
From a traditional arithmetic perspective, H20 is a downgrade from H100, but in this aspect of LLM inference, H20 will actually be over 20% faster than H100..
I assume H20s are cheaper than H100, which means tokens per dollar is a better deal with H20 than H100.
So I suppose we will see increased demand for smaller GPUs and GPUs with better memory bandwidth (see this).
What it means for CUDA
CUDA is like the air we breathe. It’s invisible, but remove it and everything will come to a halt. Without a doubt, it’s widespread use has been a contributing factor to nvidia’s dominance. But now DeepSeek seems to have worked a layer below CUDA. Perhaps this is a sign of things to come?
From Tom’s hardware:
DeepSeek made quite a splash in the AI industry by training its Mixture-of-Experts (MoE) language model with 671 billion parameters using a cluster featuring 2,048 Nvidia H800 GPUs in about two months, showing 10X higher efficiency than AI industry leaders like Meta. The breakthrough was achieved by implementing tons of fine-grained optimizations and usage of assembly-like PTX (Parallel Thread Execution) programming instead of Nvidia's CUDA, according to an analysis from Mirae Asset Securities Korea cited by u/Jukanlosreve.
What it means for Nvidia
Imagine a party going on in a luxurious venue. The music and food is good. DeepSeek enters the scene and gets everyone energized a lot more. And people outside are clamoring to get in.
And who owns the venue and sets the ticket price?
Nvidia.
What it means for China vs. USA
DeepSeek has made it quite clear that the USA is no longer the only leading player here. China has shown that it can be a worthy rival. In addition to DeepSeek, there are other good players, like Qwen and, very recently, Kimi. Bytedance is definitely not twiddling its thumbs.
Unlike the US, China can move fast. They can deploy monstrous data centers much quicker. They can attract top talent now. They are just bottlenecked on GPUs. And then there is the tough situation with TSMC. I am not an expert here, so I will not write much more about this, at least for now.
Their rate of progress overall seems relatively fast. So, if the US wants to lead the race, some drastic changes need to happen, including more investment into research.
What it means for Censorship and alignment
Chinese models are censored and aligned with what the CCP wants. That’s why DeepSeek-R1 models can be problematic for many other countries to rely on.
There have been successful attempts to decensor the models, most notably by Perplexity and us (and we did it before Perplexity). See the previous post.
Ignoring our work that removes censoring with distillation, it’s perhaps possible that distilled models can derive their biases and censorship from the teacher models. This can be problematic.
For example, if a company uses either DeepSeek-R1 or a distilled model for sentiment detection, which feeds into a pipeline that makes automated stock trading bots, what will happen if the sentiment is somehow more favorable to Chinese companies (inadvertently or not)?
What it means for India
India has been left far behind, and they are not even in the race for practical purposes. It is painfully evident now that they lack the resources, talent, and, unfortunately, the willpower. There are plenty of very smart individuals, but if they can be organized towards one mission, India can recreate the magic of ISRO. But it’s not happening yet. Sarvam is doing the only good work. Krutrim AI is a well-funded player started by Ola’s Bhavish Aggarwal, but they seem to want to be doing everything (pretrain models, GPU offering, Mapping solutions(!?)).
The path forward is likely to be that India adopts a model like DeepSeek and continues to fine-tune/post-train on top of it. But from a national security perspective, this is not ideal.
This is an excellent video from an Indian influencer (and, ironically, sponsored by a Russian company Yandex):
What it means for building Data Centers
This relates to the point of pre-training to a large extent. Post-training compute is not as intensive. For inference, we need GPUs spread across many locations, while for pre-training, we need many GPUs in one location.
Recently, xAI’s Colussus cluster had 100,000 Nvidia H100 GPUs. But DeepSeek (if we were to believe their numbers) used a lot fewer GPUs for pre-training. And so if that plays out, perhaps we don’t need monstrous data centers. But that’s not how it will play out. People will continue to scale at least for a few more years.
The kind of issues you will see when you train with 100k GPUs is vastly different from those you will encounter at 1000 GPUs scale. Everything that can go wrong will go wrong, and some more. Cosmic rays will flip the bits. Liquid cooling is messy. How do you get the right amount of power to support 100k GPUs? People are spinning up new coal plants, and overall, it looks like we have figured out nuclear fusion. As Dylan says, innovation is happening at all levels (including, say, in how to do refrigeration).
Concretely, its unclear if US companies will try to immediately scale down even though DeepSeek showed the way.
What it means for Inference Providers
The inference providers in the US (and elsewhere) have been struggling with inference. We lucked out in between with DeepSeek’s API, but overall, getting the tokens from US providers has been a struggle. A few people came forward, boldly claiming they could easily host DeepSeek-R1 models. When asked for more details, I found out that it’s the 8B distilled version of Llama. How am I to train a 32B version from it?
Recently, DeepSeek open-sourced a few infra libraries and provided some details on their serving statistics. Their central claim seems to be that they are set to achieve a 545% theoretical profit margin. However, they haven’t fully packaged everything and released it, so nobody else has been able to reproduce their claims.
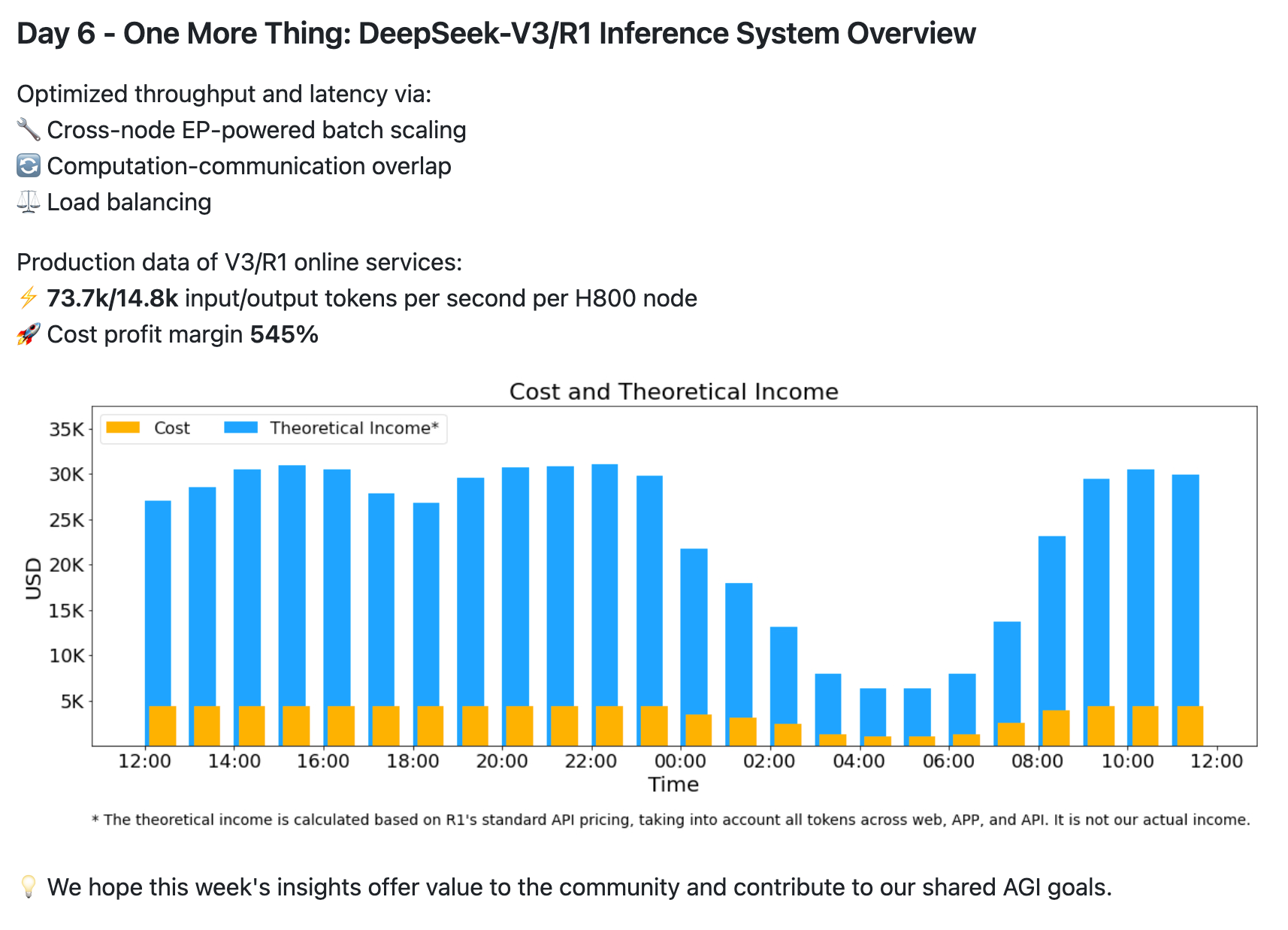
This is insane. While many other providers struggle to provide inference and charge a lot higher, DeepSeek claims to be set to make profits.
Perhaps this is like the four-minute mile marker. Given that they have said this is doable and given some details, we hope that the other providers can catch up (and outdo). What we need for this is a good old American innovation spirit.
What it means for AGI
My personal belief is that if there is one thing that will give us AGI, it’s RL. The frontier labs know the importance of RL, and DeepSeek has spilled this secret into the open. We will master reasoning. And then agents that run reliably for a minute, then ten minutes, and then a day or two. Like the proverbial frog that doesn’t know the water is boiling, we will one day wake up and may not even realize we live in a different world.
If you made it this far, thank you for reading. This is my first such long post. Hope to share more insights, so please subscribe: